これは何
今回モノレポ管理ツールを Nx から Turborepo へと移行したのですが、ポリレポからモノレポへの移行に関する記事はあっても管理ツールのリプレイスというのはあまり見当たらなかったため、その知見を共有したいと思います。
弊社サービスとフロントエンドの構成について
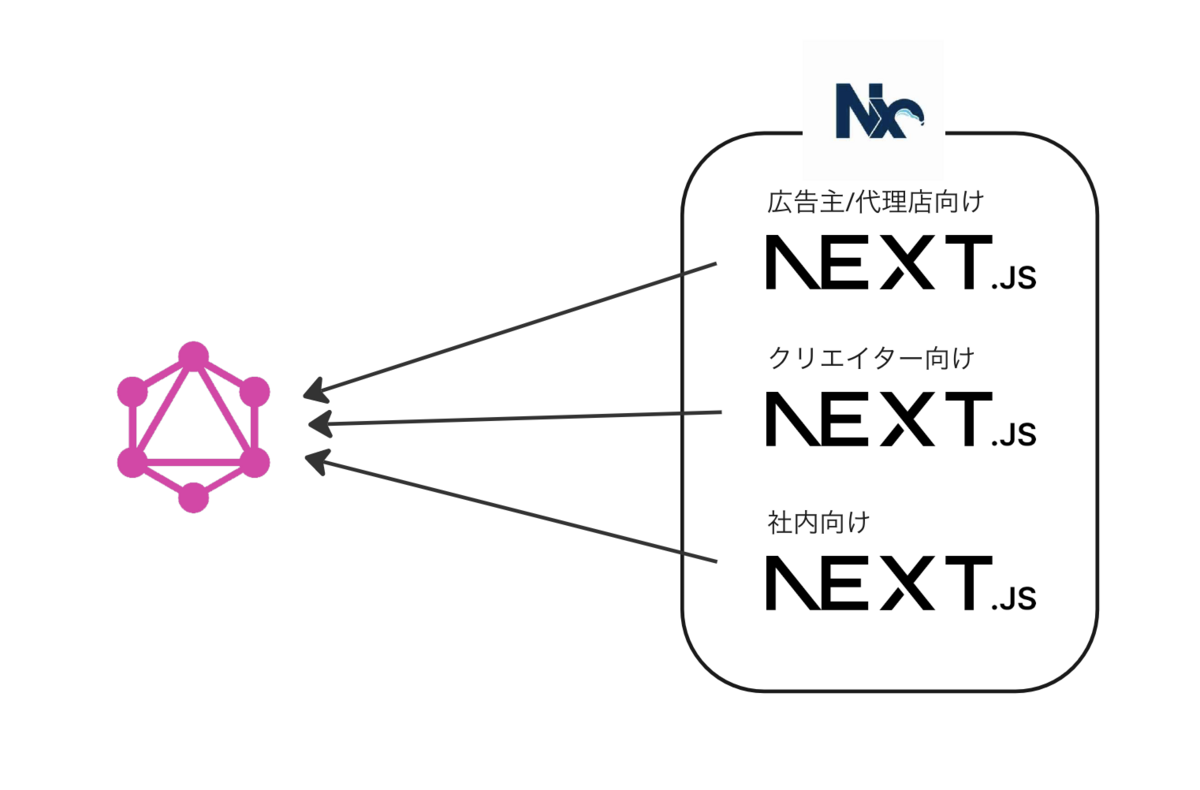
identify株式会社で副業エンジニアとして主にフロントエンドをお手伝いしている @uekenu です。 弊社identify株式会社では動画素材サービスDeLMOの運営を行っています。DeLMOは動画をダウンロードする広告主様/代理店様と動画提供者のクリエイターに利用いただいており、そこに特権管理者である弊社のスタッフを加えるとユーザーの属性としては3種類に分けることができます。そして3種のユーザーにそれぞれ別々の環境の画面を用意しています。
アーキテクチャとしては、バックエンドに GraphQL サーバーがあり、そこを叩くフロントエンドが3環境あるという構成になっています。
- 広告主様/代理店様向けのサービスサイト
- クリエイター向けの管理画面
- 社内向けの管理画面
これらはそれぞれ Next.js で別々のアプリケーションとして構築されており、 1つのリポジトリ内で3つのプロジェクトを管理するモノレポ構成を Nx によって実現しています。
Nx を採用した理由と現状の課題
モノレポを構築する際、各 app の依存関係やビルドコマンドの実行順などの管理をツールに任せたいと考えました。当時最も人気のあるツールは Lerna でしたが、その時点でほとんどメンテされてないという点と Nx が台頭してきているという点から Nx を採用しました。
しかし、運用していく上で以下に挙げるような問題が顕在化してきました。
バージョンアップがつらい
Nx は Next.js へのサポートをプラグインによって実現しているため、 Next.js をバージョンアップするためには Nx のプラグイン、ひいては本体も上げないといけないというケースがよくありました。 Next.js は積極的に新機能を打ち出してきますし、できるだけ追従していきたいところです。
しかし、 Nx のバージョンアップには様々な障壁がありました。例えばマイナーバージョンアップでビルドが通らなくなったりする問題が相当数報告されており、実際に弊社も何回か遭遇しその度に問題バージョンの特定を切り分けによっておこなったり公式リポジトリの issue を掘ったりしていました。 私たちもハマったものでいうと例えば以下のような issue が挙げられます。その度にメンテナが誠意ある対応をしてくれているのですが、私たちとしてはバージョンアップのたびに疲弊していたというのが正直なところです。
- On nx 15.8.7 can't build Next app (13.1.6 nor 13.2.4) #15794
- React build breaks after migrating to 15.5.1 #14389
- Cannot find module '@nrwl/webpack/package.json' #14531
ビルドが不安定
本プロジェクトは Next.js を Vercel にホスティングしているのですが、ある時から Vercel 上でのビルドが以下のようなログとともに失敗する状況に陥りました。しかも成功する時と失敗する時が混在しているのです(体感1~2割程度で失敗)。
. . . Vercel CLI 28.18.1 Installing dependencies... yarn install v1.22.17 [1/4] Resolving packages... success Already up-to-date. Done in 0.83s. Detected Next.js version: 13.1.1 Running "yarn nx run accounts:build --skip-nx-cache --verbose" yarn run v1.22.17 $ nx run accounts:build --skip-nx-cache --verbose error Command failed with signal "SIGTERM". info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command. Error: Command "yarn nx run accounts:build --skip-nx-cache --verbose" exited with 1 BUILD_UTILS_SPAWN_1: Command "yarn nx run accounts:build --skip-nx-cache --verbose" exited with 1
いまいちログの内容が薄いため原因の特定が難しく、 Vercel に問い合わせたところ Nx の問題で失敗しているらしいのでバージョンアップなどを試してほしいといったような回答をもらったのですが、バージョンアップしても改善せず、そのまま脱 Nx のきっかけとなりました。
単一の package.json
Nx はプロジェクトルートに単一の package.json を持ちます。最初の頃は全 app 共通で依存関係を管理できるのが楽でしたが、時間が経つにつれライブラリのリプレイスやバージョンアップ時に影響範囲を調べるのが大変になり、ビッグバンアップデートもせざるを得ない状況となっていきました。
こうした問題と向き合い、頑張って Nx を使いこなせるようになるよりも、他のツールに移行し、シンプルな構成にすることでモノレポの長期的な運用コストを下げたい、というものが今回の移行の背景となりました。
移行先の選択肢
Turborepo
- Vercel が提供
- Workspaces ベース
Rush
https://rushjs.io/pages/contributing/
- Microsoft が提供
- ビルドコマンドやパッケージアップデートなどは全て
rushコマンドでおこなう - Nx と同じ複雑性を抱えそう
yarn Workspaces
https://yarnpkg.com/features/workspaces
- yarn 以外に特別なツールは必要ない
そもそもモノレポをやめる
app ごとにリポジトリを作成しポリレポ構成に戻すという選択肢もありましたが、
- フロントエンドを触る際に社内向け画面とクリエイター画面など複数の環境を同時に触ることがあり、そのような修正を一つの Pull Request で行いたいケースが存在する
- 1つのリポジトリにフロントエンド環境が全部揃っているとコードを参考にしやすく、コードを似せて書きやすくなる
といった事情から、基本的にはモノレポのままいく前提で考えました。
Turborepo にした理由
構成がシンプル
Turborepo は実質的に yarn workspace をラップしている程度の構成と認識しており、それに追加で必要な設定ファイルは turbo.json のみなので非常にシンプルです。将来的にやっぱり Turborepo をやめたいとなっても比較的容易に生の yarn Workspaces に戻せるため、同等の他のツールへの移行もしやすいのではないかと考えました。
Remote Caching
Turborepo には Remote Caching という機能があります。ローカルでのビルドをチームで共有できるもので、 CI やローカルでキャッシュヒットすればビルドを高速化させることができます。 同様の機能は Nx も提供していますが、 Nx Cloud というサービスに別途登録と課金が必要です。 Turborepo の Remote cache はホスティングサービスとしての Vercel が対応しており、 Team plan であれば無料なので、すでにそのプランである私たちにとってはそのまま使えました。
Vercel 社が出してる
身も蓋もありませんが、意思決定においてそれなりに大きい割合を占めました。 基本的にはベンダーロックインは忌み嫌われがちなものですが、私たちは Vercel 社に対してのロックインは例外的に許容しています。本記事の趣旨とずれるので割愛しますが、Next.js の使いやすさなどが理由です。Turborepo は Vercel 社が提供しているため、 Next.js やホスティングサービスとしての Vercel と当然相性がよく、特に後者はほぼゼロコンフィグでいい感じになりました。
補足: yarn Workspaces でいいのでは?
今回実現したかったことはパッケージ間の依存関係を管理できている状態は保ちつつシンプルな構成にすることだったので、 yarn Workspaces で十分要件は満たせそうではありました。
しかし、 Vercel は今後 Turbopack というバンドルツールと Turborepo を統合し Turbo という単一のツールチェーンの開発に力を入れていくようです。将来的に Webpack から Turbopack へ乗り換えることでビルド速度の向上も期待できそうなこともあり、このあたりのエコシステムに早めに乗っかっておこうという方針で Turborepo の導入を決めました。
手順
Turborepo は yarn / npm / pnpm の各パッケージマネージャが提供する Workspaces の上に構築されています。そのため、移行は以下のような手順で進めました。
- Nx を剥がし、単純に1つのリポジトリ内に3つの Next.js が同居している状態にする
- Workspaces を導入
- Turborepo を導入
Nx を剥がす
移行前の状態は Nx が示す規約に従い
/ ├ apps │ ├ accounts │ │ └ tsconfig.json │ ├ creator │ │ └ tsconfig.json │ └ admin │ └ tsconfig.json ├ nx.json ├ package.json └ tsconfig.base.json
このようにプロジェクトルートに1つの package.json を持っていました。ここから
/ └ apps ├ accounts │ ├ package.json │ └ tsconfig.json ├ creator │ ├ package.json │ └ tsconfig.json └ admin ├ package.json └ tsconfig.json
このように各 app がそれぞれ個別の package.json を持っているような状態を目指します。
まずは Nx 関連の依存を全て剥がしていきます。主にやることは .eslintrc や next.config.js などに入り込んだ各種プラグインの削除となります。その後 package.json から Nx 関連の dependencies を remove すればOKです。
Nx は tsconfig.base.json をプロジェクトルートに持ち、各 app がそれを extend するようにしており、 .eslintrc 等も同様に共通した設定はルートにベースとなる設定ファイルを置く構成となっています。そこで、 Workspace 化するまでは共通設定ファイルはルートにそのまま置いておき、各 app に個別に置いた設定ファイルから相対パスで参照し extend するようにしておきます。
{
"extends": "../../tsconfig.base.json",
"compilerOptions": {
.
.
.
}
}
次に、各 app で yarn init し package.json を設置します。
cd apps/accounts && yarn init -y cd ../creator && yarn init -y cd ../admin && yarn init -y
最後に、ルートの package.json 内の dependencies および devDependencies 群を各 app にコピーしてきます。また、この時 Next.js のデフォルトの scripts も記述しておきます。
{
"name": "creator",
"version": "1.0.0",
"license": "MIT",
"scripts": {
"dev": "next dev",
"build": "next build",
"start": "next start",
"lint": "next lint"
},
"private": true,
"dependencies": {
// ルートの package.json の dependencies
},
"devDependencies": {
// ルートの package.json の devDependencies
}
}
ここまでくれば、ルートの package.json を削除できるかつ各 app のディレクトリ内で Next.js が動くようになります。
rm package.json cd apps/creator yarn yarn dev
以上で、無事に Nx を脱却し、3つの素朴な Next.js アプリケーションが1リポジトリ内にただ同居している、という状態にすることができました。
Workspaces を導入
本プロジェクトはパッケージマネージャーに yarn を使っているため、 yarn の Workspaces を導入しました。
まずはプロジェクトルートに yarn init -y で package.json を設置します。その後、 apps 以下のディレクトリを app として読み込むようにします。ついでに共通パッケージを置く場所として packages も追加します。
{
"name": "delmo-frontend",
"version": "1.0.0",
"license": "MIT",
"private": true,
"workspaces": ["apps/*", "packages/*"]
}
共通パッケージの設定については Turborepo の example が非常に参考になると思います。
https://github.com/vercel/turbo/tree/main/examples/basic
簡単に説明すると、例えば tsconfig なら
packages/tsconfigで新規パッケージを作成package.jsonの name は例えば@delmo/tsconfigとしておく
- プロジェクトルートに置いてあった
tsconfig.base.jsonを作成したパッケージに移動 - 利用したいパッケージ側の dependencies に
"@delmo/tsconfig": "*"として追加 - プロジェクトルートで
yarn install
このようにすれば、パッケージ間で参照できるので以下のように extend を変更することができます。
{
"extends": "@delmo/tsconfig/base.json",
"compilerOptions": {
.
.
.
}
}
Turborepo を導入
ここまでくれば Turborepo の導入は以下の通りにすれば特に詰まることなくスッと入ると思います。
https://turbo.build/repo/docs/getting-started/existing-monorepo
Turborepo は global にインストールすることもできますが、メンバー間の環境差異を極力無くしたかったため local インストールとしました。
yarn add -D turbo
続いて turbo.json という名前で Turborepo の設定ファイルを作成します。
{
"$schema": "https://turbo.build/schema.json"
}
turbo.json にはプロジェクトルートの package.json に記述された各スクリプトの依存関係やキャッシュを pipeline として定義します。
{
"$schema": "https://turbo.build/schema.json",
"pipeline": {
"build": {
"dependsOn": ["^build"],
"outputs": [".next/**", "!.next/cache/**"]
},
"test": {
"dependsOn": ["build"],
"inputs": ["src/**/*.tsx", "src/**/*.ts", "test/**/*.ts", "test/**/*.tsx"]
},
"lint": {},
"deploy": {
"dependsOn": ["build", "test", "lint"]
}
}
}
ここに定義したコマンドは各 app の package.json に同名のスクリプトとして定義し動くようにしておく必要があります。例えば lint は各 app 上で yarn lint として動くようにしておき、 turbo.json にも定義するとプロジェクトルート上で npx turbo run lint を叩くことができるようになり、各 app 上で eslint を走らせ実行結果をキャッシュしてくれます。
最後に Vercel でのビルドの設定を変更します。
Root Directory を各 app のディレクトリとするだけで大丈夫です。

以前はプロジェクトルートに戻ってから単一 app のみのビルドをする必要があるため Build Command を cd ../.. && yarn build --filter=app-name と設定する必要があったようですが、今は Vercel がコマンドを推論してくれるようになっているため設定は不要です。
以上で、次回のビルドから Turborepo のビルドが走るはずです。
また、 app 内にコードの差分がなかった場合にビルドのスキップをしたい場合は、 こちらを参考に Settings -> Git の Ignored Build Step を以下とします。
npx turbo-ignore
はまったポイント・うまくいったポイントなど
プロジェクトルートの package.json が読めずパッケージ間の参照ができない
開発中に以下のようなビルドエラーが発生しました。
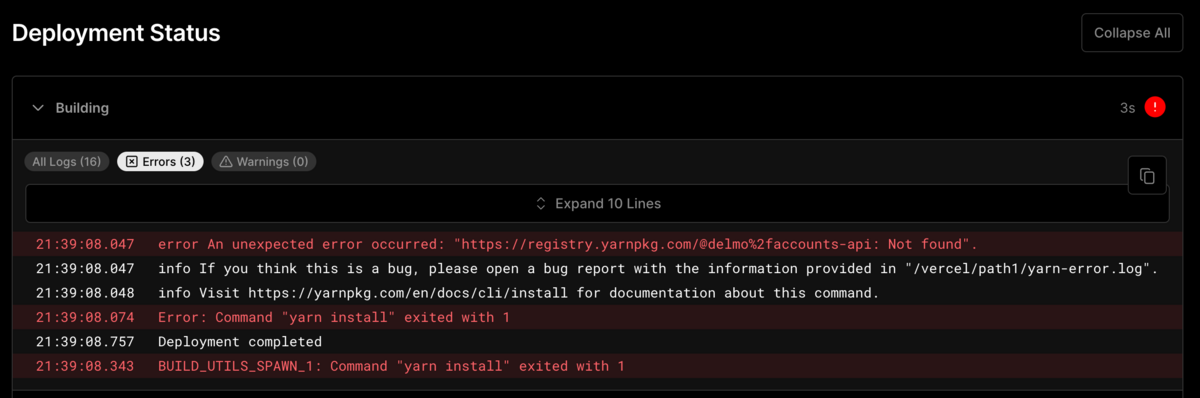
これは、 Vercel の Project Settings のうち、以下の Include source files outside of the Root Directory in the Build Step. のチェックが外れており、プロジェクトルートの package.json が読めず workspace が無効になってしまっていたのが原因でした。
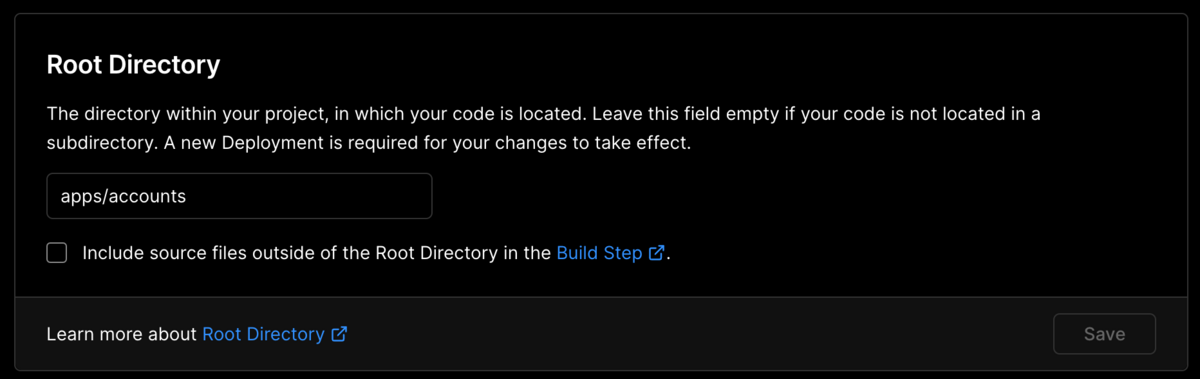
上記のチェックを入れることで解決しました。
CI で node_modules のキャッシュが引けなくなった
Nx ベースだと node_modules が root にしかなかったため、 CI でキャッシュする際はそこだけで事足りました。 Turborepo にしてからは apps 以下にそれぞれ node_modules を作るようになったので、キャッシュの取り方を変更する必要がありました。
$ git diff
diff --git a/.github/workflows/build.yml b/.github/workflows/build.yml
index 63542ce0..b3312acd 100644
--- a/.github/workflows/build.yml
+++ b/.github/workflows/build.yml
@@ -21,7 +21,7 @@ jobs:
- name: Restore node_modules cache
uses: actions/cache@v2.1.5
with:
- path: 'node_modules'
+ path: '**/node_modules'
key: yarn-cache-${{ hashFiles('yarn.lock') }}
- name: Install yarn
本番適用において Instant Rollback が精神的な支えとなった
移行の本質とはずれますが、 Vercel には Instant Rollback という機能があります。簡単に言うと以前のデプロイの状態に瞬時に戻せる機能です。
ツールの移行に伴い、 Vercel 上の設定や環境変数が大きく変更になるため、リリース後に本番環境において問題が生じないか精神的に不安な部分がありましたが、何か起きてもこの機能を使えばすぐにロールバックできるため、比較的安心して本番適用を進めることができました。
移行してみてどうなったか
Nx 時代のコードベースと比べると、 Turborepo にしてからは以下のような点で運用負荷が軽減されたように感じています。
- 各 app をそれぞれ独立したアプリケーションと見なしやすくなったこと
- ビルドの安定性が増したこと
- ツール固有のプラグインがなくなり、設定も減ったこと
一方で、 Turborepo の強みの一つである Remote Caching はまだチームとして使えていません。
現状だと .gitignore に含まれていない全ファイルを巻き込んでハッシュにし、それをキャッシュキーにしているので、恩恵を受けることができるのが git clone 直後の初回のビルドくらいでは、と考えているためです。また、適切な設定をおこなわないと誤った環境変数がビルドキャッシュに含まれる可能性があるなど、ビルド時間を短縮するという目的にしては必要以上に複雑性を抱えそうな気がしています。
今後、コードの差分のみをビルド対象とし他の部分はキャッシュをいい感じに使ってくれるようになると嬉しいな、などど考えています。
最後に
弊社ではソフトウェアエンジニアを募集しております。 @suthio にDMしていただくか、下記での応募をお待ちしております。